Focus on the data - we'll manage the infrastructure!
Cloud infrastructure that simplifies how you process, analyze and transform data.
About #Let's Data
#Let's Data simplifies the creation and management of data and compute pipelines using AWS services.#LetsData provides turn-key infrastructure for common data tasks using AWS. #Let's Data pipelines are designed for companies investing in data infrastructure for their business. ROI for a small sized data team is ~ 20% ($540K) savings annually on an AWS spend of ~ $40K per month, primarily from headcount reduction. Switching costs payback time has been estimated at ~1.8 months
The Problem
Here are some axiomatic truths about the relationship of data and the enterprise:
- Enterprises are creating data at an ever-faster pace: Clickstreams are logged, screen times are emitted, Ad interactions are recorded and even the performance statistics are logged. A single user session can potentially generate hundreds of megabytes of data per day.
- Data is fragmented: The data in the enterprise is fragmented. There is no "one-size-fits-all" data store. Today the data is stored in log files, databases, in-memory caches, messaging queues etc. Log files need to be processed to extract events and derive intelligence. ETL jobs on database are run frequently to get data in formats used by different systems. In-memory caches need to be populated, refreshed and reconciled with data sources. Data in messaging queues bridges the data from sources and consumers. Let's face it, this fragmented data needs to be processed, analyzed and transformed for different business needs
- Agility is a key business differentiator:Agility in being able to respond to different data transformation needs is a key business differentiator. Organizations that invest in data infrastructure to build production systems that can manage the data requirements are more successful than orgs that do not have dedicated infrastructure. Data agility is a key business differentiator in the enterprise.
- Data Infrastructures are costly:Building data infrastructures are costly. There is a cost to build, manage, maintain and evolve the data infrastructure constantly as the business needs change. The costs are complex, data engineers need to be hired, infrastructure needs to be acquired (or leased), code needs to be written and managed and operations need to be staffed.
- Data Infrastructures may not be the core business:Organizations whose core business is not data management find it increasingly difficult to build, maintain and even justify the costs related to data infrastructures. A retailer's core is inventory, selection, marketing and sales. Data augments these functions and being able to leverage a data infrastructure should not be prohibitive for such organizations
The data infrastructure needs to be robust, reliable and fault tolerant that is maintainable, operable and resilient. Each data processing, analysis and transformation requires custom compute code which isn't trivial – example, transient failures, rate limiting, batching, ordering and deduplication, checkpointing and failure restarts need to be handled for each destination. Logging, Metrics and Diagnostics need to be built in.
These tasks have nothing to do with the actual customer data / data transformation logic. Instead, they are the engineering grunt work required to build data compute infrastructure that can read reliably from the data source and write efficiently to the data destination.
This data compute infrastructure development happens again and again for different data sources and destinations, for different functional domains within the enterprise.
The Let's Data Value
#Let’s Data simplifies data pipelines and eliminates infrastructure pains. Our promise: "Focus on the data, we'll manage the infrastructure".
We've perfected our infrastructure code for AWS Services and built all the reliability, fault tolerance and diagnostics needed for a high-quality compute pipeline.
- Faster development times (42 dev weeks reduced to 8 dev weeks - Web Crawl Archive Case Study)
- Reduced costs (ROI calculations for a small sized data team suggests ~20% ($540K) savings in 1 year on AWS spend of ~ $40K per month, primarily from headcount reduction. Switching costs payback time is estimated at ~1.8 months
- Simplified development and reduced system complexity The #Let's Data Simplification Architecture Diagram
- Standardized development and operations (Full featured CLI, Console, logging, errors, metrics and task management builtin)
- High Performance & Elastic Scale (In a web crawler case study, #Let’s Data processed 219K files (~477 TB) from S3 using Lambda in 48 hours at a nominal cost of $ 5 per TB-Hour!)
- Zero cost version updates (AWS SDK upgrades, #Let's Data version upgrades etc.)
#Let's Data defines simple interfaces for developers to transform records - #Let's Data will read from AWS, write to AWS and takes care of the performance, errors, diagnostics and everything in-between.
#Let’s Data Minimum Viable Product (MVP) currently supports:- S3
- DynamoDB
- SQS
- Kinesis
- Lambda
- Kafka
- Sagemaker
- Momento Vector Index
- Spark
- us-east-1 (N. Virginia)
- us-east-2 (Ohio)
- us-west-2 (Oregon)
- eu-west-1 (Ireland)
- ap-south-1 (Mumbai)
- ap-northeast-1 (Tokyo)
Here are some features at a glance:
- Connectors: #LetsData understands the different sources and destinations that data is read from and written to. We've built scalable infrastructure to read and write to these destinations reliably at scale. For example, AWS S3, SQS, DynamoDB and Kinesis etc. This simplifies the customer data processing since they do not need to invest resources to build these infrastructure components.
- Simple Programming Model: #LetsData defines a simple programming model inspired by the AWS Lambda event handlers - For example, customers implement a simple interfaces to tell us the start and end of records in an S3 file, we read the file and send them a completed record which they can transform and return to the framework to write to the destination
- Compute: #LetsData has built end-to-end automation around the popular processing frameworks such as AWS Lambda - this allows the customers to customize the processing framework according to their needs and scale at which they want to operate. For example, when processing log files from S3, running on network configuration with 100Gbps network to get maximum throughput etc.
- Diagnostics: #LetsData infrastructure builds in summarized and detailed logging, execution traces and adds metrics for each step in the pipeline. This allows the customers to monitor and measure the progress of their tasks and tune the workflow as needed.
- Errors & Checkpointing: Infrastructure components such as Error Reports, Redriving Error Tasks, Checkpointing etc are built into the framework - customers can rely on these to ensure high quality
- Costs Management: #LetsData allows high scale at efficient costs. We've built in cost optimization engines that monitor for cost reduction opportunities and de-scale/ reclaim resources to ensure efficient management of costs. Costs Management and Costs Transparency is also built into the website - customers can track and manage costs as needed.
The #Let's Data Value
Process data from a number of different data destinations, AWS S3, AWS Dynamo DB, AWS Kinesis, AWS SQS etc.
Implement the simple data interface, create a dataset job & viola! It's done!
Achieve high scale with our built-in infrastructure!
We've built-in diagnostics, user management, data lifecycle, cost optimizations so that you don't have to!
Reduced TCOs! Low costs and cost optimization engines are built-in!
Architected using secure data principles - dedicated tenancy and credential scoping for data handlers
 AWS Trusted Partner
AWS Trusted PartnerReviewed By AWS For Following AWS Best Practices



Big Data: Building a Document Index From Web Crawl Archives
Download PDFAbstract
In this big data case study, we processed the Common Crawl Web Archives files using the #Let's Data. Common Crawl is an open repository of web crawl data and a fantastic resource for the www web crawl data. https://commoncrawl.org/
We used #Let's Data compute to reduce the web archives to JSON documents that could be used to create a database index. We processed ~ 219K files, ~477 TB S3 data in 48 hours at a nominal cost of $5 per TB-Hour.
Problem Definition
Big Data datasets are generally huge datasets spread across a large number of files. Processing these files at high scale and in a reasonable amount of time requires creating a data pipeline which can be a significant engineering infrastructure effort, is rife with infrastructure costs and can take many man-months to build and perfect. In this Big Data use-case, we want to process the Common Crawl Web Archives files (219K files, 477TB uncompressed data) and transform this semi-structured data to structured JSON documents that can be used to create a database index. Such an effort would require an understanding of the data domain (Common Crawl Web Archive Formats), infrastructure challenges such as reliable and fault tolerant compute infrastructure, maintainability, operability and non – trivial compute code. For example, the compute code needs to deal with transient failures, rate limiting, batching for performance, ordering and deduplication, checkpointing and failure restarts etc. Logging, Metrics and Diagnostics infrastructure need to be built in. Building such a dataset pipeline on #Let's Data eliminates these infrastructure requirements – the #Let’s Data promise is that the enterprises should "Focus on the data, we'll manage the infrastructure". We used #Let’s Data to process the Common Crawl Web Archives dataset – the system processed 219K files, ~477 TB of data in ~ 48 hours and extracted ~3 billion JSON documents – this roughly translates to a TPS of 17K documents per second! #Let’s Data simplified the creation and management of this data compute pipelines using AWS services, reduced the development time, costs, enabled high performance, availability, and elastic scale.Solution & Architecture
There are two different types of development efforts needed for such a Big Data use-case:- The Functional Data Model: Understanding the data formats for the big data functional domain and developing how to parse the data and extract output documents.
- The Data Pipeline Infrastructure: This is the infrastructure code that is required to orchestrate the data pipeline, reading from the source, writing to the destination, scheduling computation tasks and data jobs, tracking errors and building in fault tolerance and the necessary diagnostics.
In traditional data pipeline development, one would spend a disproportionately large development effort in developing the data pipeline infrastructure. With #Let’s Data, the focus is mostly on developing the functional data model, with only an integration effort to orchestrate and run the data pipeline.
Let’s look at each of these development efforts in detail.
Common Crawl Data Model
The Common Crawl Dataset has the following characteristics:
- it has three filetypes the Archive, Metadata and Conversion files
- each data record (crawled link) has data that is spread across these three files:
- the archive file has the http request and response with some high level metadata
- the metadata file has the metadata about the records in the archive file such as record types and their record offsets etc.
- the conversion template has the converted Html document
- each of these files follows a record state machine for each data record (crawled link) – for example,
- the archive file state machine is REQUEST -> RESPONSE -> METADATA for each crawled link
- the metadata file state machine is METADATA (Request) -> METADATA(Response) -> METADATA(Metadata) for each crawled link (remember that this is metadata about the archive file records)
- the conversion file state machine is simple – a single CONVERSION record for each crawled link
With this high-level information, we do the following development tasks:
- The POJOS: create Java POJOs that map to each record type – this is the majority of the work, where you define how to create an object from a byte array and validating the integrity of the object.
- The Parsers: define a parser state machine for each of the file using the #Let’s Data interfaces – this is relatively simpler, you encode the record types as a state machine and specify the start and end delimiters for each records
- The Reader: define a reader that constructs an output document from these file parser state machines using the #Let’s Data interface – this is the simplest of the three, encode the record retrieval logic from the parsers and then construct an output record by combining the these.
We’ve shared our implementation of the common crawl model at the Git Hub repository: https://github.com/lets-data/letsdata-common-crawl
#Let’s Data Data-Pipeline
With the above common crawl data model, we can now simply orchestrate the data pipeline by specifying the dataset configuration. We’d be creating a pipeline that reads the common crawl dataset files from AWS S3, writes them to AWS Kinesis and uses AWS Lambda to run the parser and extraction code. We also do some access setup so that #Let’s Data can automatically manage the read and write resources.
Here are the dataset configuration details:
- Read Connector configuration:
- the S3 Bucket to read from
- the JAR file that has the #Let’s Data interface implementations
- the mapping of #Let’s Data interfaces to file types (archive file type -> archive file parser class name etc.)
- Write Connector Configuration:
- the Kinesis stream that we need to write to
- the number of shards for the Kinesis stream
- Error Connector Configuration:
- the S3 Bucket to write the error records to
- Compute Engine Configuration:
- AWS Lambda compute details – these are the function concurrency, timeout, memory and log level
- Manifest file:
- the manifest file that defines the list of all the files that should be processed and their mapping – example:
- Each line in the manifest file becomes a #Let’s Data task that can be tracked from creation to completion and has its own progress, errors and diagnostics tracing.
We use the #Let’s Data CLI to create this dataset and monitor its execution via the CLI and Console.
Results
We ran this common crawl use-case on #Let’s Data to test the limits of our infrastructure and were pleasantly surprised by the staggering scale we were able to achieve at nominal costs. Here are some results at a glance:
- The system processed 73220 tasks out of the 80000 tasks in ~ 48 hours
- Tasks executed on AWS Lambda with a concurrent execution of 500 Tasks
- 219K files processed, read 477 TB of uncompressed data from S3, wrote 13 TB to AWS Kinesis.
- Extracted ~ 3 billion records that were written to AWS Kinesis Stream. ~16 million error records were written to AWS S3 as error records (0.5 % errors). (To put the 3 billion number into perspective, Google processes around 8.5 billion searches per day Source)
- The system peaked at reading 455 GB per minute from S3 and writing 12.36 GB per minute in AWS Kinesis, extracting 2.7 million records per minute (~45K records per second!)
- The costs for the dataset were $36,000 - approx. cost of $75 for each TB (uncompressed) and a $1.67 per TB-Hour
TCO Analysis
Developing on the #Let’s Data infrastructure has huge cost and time savings – here is a side by side comparison:
This is a 5X reduction!
How we built it?
- Code the Common Crawl Web Archive data model classes. Here is the common-crawl model that we built
- Implement 3 #Let's Data Parser Interfaces: WARCFileParser, WATFileParser, WETFileParser for the Common Crawl File Types
- Implement 1 Reader Interface: CommonCrawlReader with logic to combine extracted records into an index document.
- Implement SingleDocInterface: IndexRecord and CompositeDocInterface CompositeIndexRecord
- Create a manifest file to define the different tasks we want processed in the dataset. Here is the script we used to create the manifest file
- Create a dataset job on #Let's Data. Here are the CLI Commands to create the dataset. Create Dataset
- Monitor the dataset execution
- Monitoring task progressList Tasks
- Viewing metrics - see the example dashboard above. The raw data can be obtained by View Metrics
- Viewing task execution logsView Logs
- Monitoring errorsView Errors
- Re-driving error tasks on #Let's DataTasks Redrive
- Monitoring task progressList Tasks
Lessons Learnt
Lessons Learnt This case study validated our engineering MVP – we can process large datasets at scale with a large reduction TCO. The case study also did find issues that we fixed:
- Simplified dataset configuration removing redundant / not needed fields
- Schema fixes where data partitioning was not working effectively for large datasets
- Initialization workflow fixes – 80K task ingestion caused our initialization workflow to timeout
- Enable Log Levels – verbose logging was enabled during the test run which resulted in a larger than expected amount of logs (and costs)
- Token Sizes – We generate a of tokens dynamically on each API call - with 80K tasks, the difference between a 1024 bytes pagination token vs a 512 bytes pagination token quickly adds up
- we were hitting API response size limits and such reductions doubled the number of results we could return in each page. - Manually tweaked the AWS Kinesis Stream's shard scaling during the run which accounts for difference in throughput and latencies during the run – need to write a dynamic optimizer (scaler / descaler)
- This was the first real large scale test of the system - while the system performed really well, we made a large number of fit and finish fixes across the stack
Product
Architecture
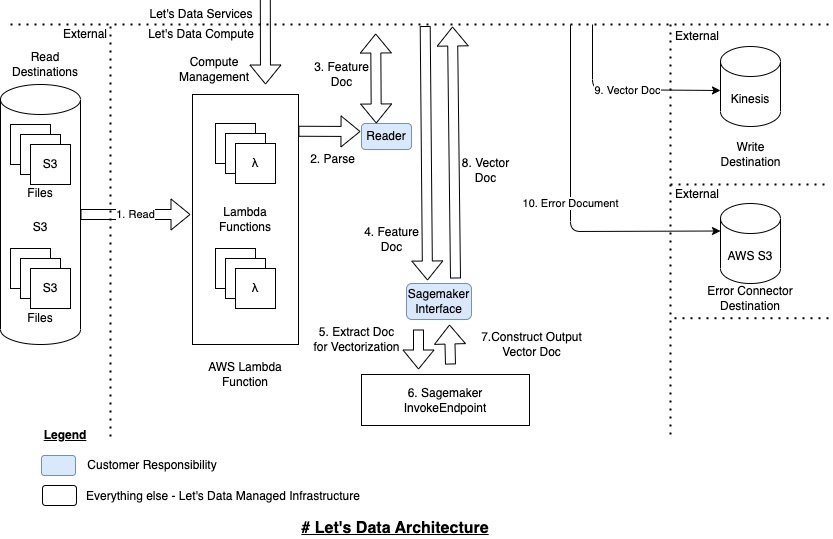
A couple of reference architectures for processing data with #LetsData. Interesting point to note is that the customer only needs to implement the components (shaded in blue) - everything else is infrastructure managed by #Let's Data. (Re-iterating our promise - "Focus on the data, we'll manage the infrastructure")
Architecture: Gen AI - Generate Vector Embeddings
References
Downloads
Interface JAR
Ready to tryout #Let's Data? Download our data interface jar and get started with developing User Data Handlers for the usecases!
Here are some quick instructions to get your dev environment ready:- Download the letsdata-data-interface JAR
- Download the letsdata-data-interface sources JAR
- Add the downloaded JAR to your developer machine's local maven repository using the following command:
- Import the JAR in your project's maven dependencies in the pom.xml:
- Refer to the Interface Docs, Interface Code on Git Hub and start developing!
- To test your implementation, create a manifest file with 1 or 2 tasks and run it on #Let's Data by creating a test dataset using either the cli or the website. Look at the datasets, tasks, logs, metrics and errors to fix any issues in the dev docs.
- Fix any JAR issues and update the existing dataset's code to use the new JAR to quickly iterate on developer errors
- Task Redrives can rerun any failed tasks and can be created via the website / cli
- Once you are satisfied with the test runs, create a new dataset with manifest file containing the entire dataset tasks and be amazed at how well the system scales!
CLI
letsdata cli is a fully functional super convenient way to manage #Let's Data resources. With simplified commmands, you can create datasets, view tasks, redrive errors, list and view logs and download your metric data with ease. (Metrics are better viewed on the website, everything else is better in the cli IMHO)
Here are some quick instructions to get started with cli:
- Download the letsdata-cli.tar.gz file
- Unzip using the following command, this should create a letsdata-cli directory which has the cli JAR file and the letsdata.sh script
- Run the letsdata file (Assumes JAVA is installed on the machine and JAVA_HOME is in the path)
- The help commands work out of the box requiring no login. To manage resources, view datasets/tasks, you'll need a #Let's Data username and password. You can signup here
- Happy datasetting!!!!
Getting Started Examples
Consider looking at Examples on step by step getting started instructions on creating a dataset.
Sign Up
Sign up to use #Let's Data. Your credit card will not be charged at sign-up and they are no hidden charges. You'll pay for what you use when you create datasets and start running tasks. Look at our prices to understand how you'll be billed.
The Resonance Labs, LLC
P.O. Box 3223
Redmond, WA 98073, USA