Developer Documentation
# Let's Data : Focus on the data - we'll manage the infrastructure!
Cloud infrastructure that simplifies how you process, analyze and transform data.
Write Connectors
Write connectors are logical connections that are created to write output docs to write connector destinations. For example, an Kinesis Write Connector is used to write data to Kinesis.
Write Connectors are implemented by #Let's Data - no coding is required by the customers to write records to each destination. All the customers have to do is:
- Configure a write connector for the dataset by specifying the writeConnector in the dataset configuration JSON
- Output the documents from the user data handlers according to the requirements of the write connector destination (For example, SQS documents should be less than 256KiB in size, Dynamo DB Documents must have keys in correct format / size, Kinesis records should be less than 1 MB etc.)
Highlights
#Let's Data understands each destination and its peculiarities and has implemented each writeConnector to sort out common issues that occur in writing data to these destinations. Here are some salient highlights:
- Performance: #Let's Data also uses performance best practices to efficiently utilize the write connector's throughput and retries in cases of throttling. In future, we'd like to implement the throttles as a signal to scale-up/scale-down the writeConnector on usage and fine tune auto calc recommendations for write connector throughput at creation.
- Batching: #Let's Data implements batched writes for each destination - essentially abstracting the complex write logic from customer's code.
- Checkpointing: #Let's Data write connector comes with built in checkpointing - so task progress is saved regularly and failed tasks can be resumed from last checkpoints.
- Error Records: #Let's Data write connectors interfaces with the error connector for creating error records.
- Retries: #Let's Data understands each write destination's errors - so it knows what constitutes a transient failure and retry, what failures are non-retryable etc and efficiently manages the writes.
- Fail-Stop / Fail-Continue: Customers can configure the write connector to fail the task on an unexpected error or to create a writeConnector error record for failed writes and continue processing till task completion.
- Metrics: #Let's Data emits write progress, retry and latency metrics which can be used to detect and fix scaling issues.
Supported Destinations
We currently support the following write connector destinations:
- Momento Vector Index
- AWS Kinesis Write Connector
- AWS Dynamo DB Write Connector
- AWS S3 Write Connector
- AWS SQS Write Connector
- AWS Kafka Write Connector
Common Configuration
The write connectors need few different pieces of information that is captured in the writeConnector configuration section in the dataset. The writeConnector configuration is different for data destinations - for example, the S3 Write Connector requires a bucketName, an optional folderName and additional information to write to S3. An SQS Write Connector requires the SQS Queue Name, Fifo queue configuration and additional information to write data to SQS. However, the following writeConnector configuration is common to all writeConnector implementations:
- region: (Optional) The optional write connector region and is set to dataset's region if unspecified. The write connector region is where the write destination (queue, table, stream, index, bucket, cluster etc) is located. When the dataset starts writing, it will create clients for the write connector region to connect to these write destinations. Specify an incorrect region and LetsData won't be able to connect. Supported Regions: [us-east-1, us-east-2, us-west-2, eu-west-1, ap-south-1, ap-northeast-1]
- connectorDestination: The data destination for the connector. This can be S3, SQS or any of the supported write connector destinations.
- resourceLocation: #Let's Data needs to know how to access the write destination. If it is publicly accessible or in the customer account, set this to Customer, we'll use the IAM Role specified in the dataset's accessGrantRoleArn to access the write destination. Otherwise, set this to LetsData, we'll manage the write destination, creating queue/table /cluster etc if necessary and use #Let's Data account to access. You'll need to add access to the write destination in the IAM role's policy document. See Access Grants Docs for details
Usecases and Configuration
Each write connector may implement different types of writers for different usecases. For example, the SQS Write Connector can write to a FIFO queue (enabling message groups and deduplication) or it can write to a Standard queue. Each usecase may require different writeConnector configuration elements. Here are the different Write Connectors, the different usecases currently supported, the configuration details and a detailed explanation of the write connector's implementation.
Momento Write Connector
#Let's Data's write connector for Momento Vector Index. At a high level, here are some notable implementation details:
- Batching: The write connector writes to Momento when it has buffered 450 records in memory as 3 parallel threads each with a batch size of 150. It does a batch write for these records. Once the writes are completed, it writes any errors that were encountered and checkpoints its progress in the task.
- Ordering: The write connector supports ordered writes for each individual key.
- Failure Modes: The connector supports fail-stop (throwOnFailure: true) and fail-continue (throwOnFailure: false) failure modes.
- Retries: Transient failures are retried. Any unhandled / terminal failures / exhausted retries are thrown as task failures.
The Momento Vector Index Write Connector, with our existing Sagemaker integration, allows users to create end to end Generative AI workflows on #LetsData platform. Here is a high level reference architecture.
Config
Here are the details about the Momento Vector Index write connector JSON configuration that can be used to create new datasets to use Momento Vector Index Write Connector
- region: the region for momento vector index. Supported Regions: [us-east-1, us-east-2, us-west-2, eu-west-1, ap-south-1, ap-northeast-1]
- connectorDestination: Set this to “Momento”. This makes it the Momento Write Connector
- resourceLocation: This is set to Customer – we only support Customer resourceLocation as of now. This essentially means that customer will need to specify their ApiToken / AuthToken when creating the dataset
- momentoTokenType: The type of momento token that the user has specified. This is needed because if ApiToken is specified, we will create the index if it does not exist. If UserToken is specified, we would not be validating whether the index exists or not. We'll just be writing data to the index in this case.
- momentoAuthToken: The Momento ApiToken / AuthToken. While the token is specified as clear text in the dataset configuration, it is handled securely by #LetsData. We store the token securely in AWS Secrets Manager and access limit it to the Dataset's execution credentials. (You should see a 'momentoAuthTokenSecretManagerArn' in the write connector when the dataset has been created and the user can be given access to this secret.)
- momentoResourceType: Set this to MomentoVectorIndex for momento vector index. We intend to support MomentoTopic and MomentoCache.
- momentoVectorIndexName: The momento index name for an existing (ApiToken/AuthToken) or a not exists (ApiToken) momento vector index.
- momentoVectorIndexNumberOfDimensions: The index number of dimensions
- momentoVectorIndexSimilarityMetric: (Optional) The similarity metric for the vector index. Defaults to COSINE_SIMILARITY. Allowed values: [COSINE_SIMILARITY, EUCLIDEAN_SIMILARITY, INNER_PRODUCT]
- momentoVectorDocumentIdFieldName: (Optional) The id field name in the document that is being written. Defaults to "id"
- momentoVectorDocumentVectorsFieldName: (Optional) The field name in the document that has the vectors. Defaults to "vectors"
- throwOnFailure: If set to true, throw an unhandled exception incase there is a failure – this essentially fails the task (fail-stop). If set to false, failures are logged as error documents, and the task tries to process the file to completion (fail-continue). Defaults to false.
Access Grants
The Auth tokens specified in the dataset have access. No additional Access Grants needed.
Implementation
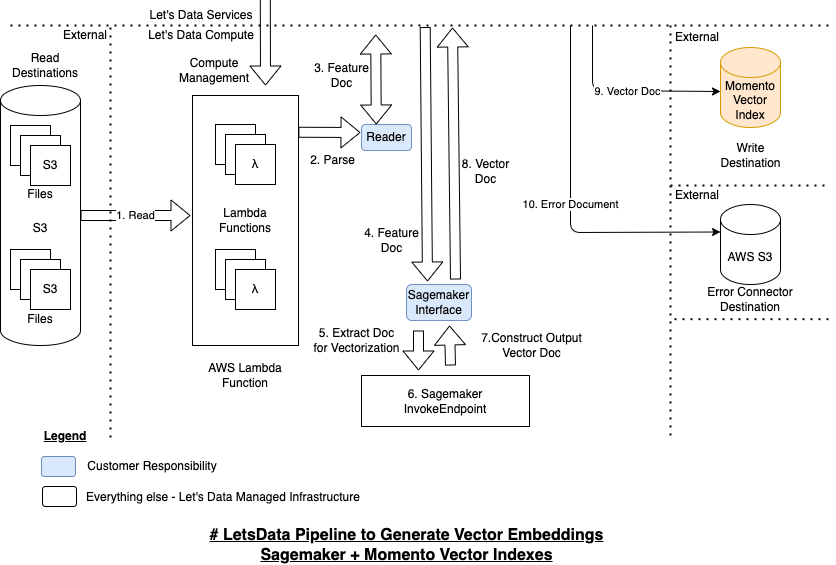
Here is a High Level Architecture Diagram of what we’ve built and tested.
- Read and Parse Feature Doc:The Lambda compute component is responsible for reading the read destination, parsing the data using the user’ data handler interface implementations and creating a feature document as before. (Steps 1-4)
- Step 1: We are using the common crawl web archives as our data source - https://www.commoncrawl.org/ - these are archive files stored in S3. We currently support S3 and SQS as read destination (publicly available) and kinesis readers (privately available) and can get a DynamoDB read connector implemented quickly as well.
- Step 2: We are using our #LetsData common crawl implementation to parse these web archives to text documents that can be vectorized: Package: letsdata-common-crawl , Codefile: CommonCrawlReader.javaIt should be important to note that if no parsing is required (data has already been parsed), this step can be a simple pass through interface.
- Step 3: Our letsdata-common-crawl code returns a document that has the Url, Html Text and other elements parsed from the Html page. Let’s call this the Feature Doc.
- Step 4: The Feature Doc is then sent to our Sagemaker interface for extraction and vector embedding generation
- Extract Doc Elements For Vectorization - Step 5:This step invokes the customers implementation of our Sagemaker interface to create a extracted doc from feature doc, essentially keeping only the fields that are needed for vectorization. Let’s call this Extracted Doc. Here is the implementation that we are using: CommonCrawlSagemakerReader.java
- Generate Vector Embeddings using Sagemaker - Step 6: The extracted elements are then sent to a Sagemaker Endpoint that generates vector embeddings.
- This endpoint is created from the user’s model code – See “Step 3: Hugging Face Sentence Transformer Model and LetsData Sagemaker Configuration” in our examples: Example - Generate Vector Embeddings
- User specifies configuration to let us know what kind of sagemaker endpoint they want – essentially, the container image for the model, the sagemaker instance hardware parameters (memory, instance type) and the number of instances in the endpoint. Here is an example config:
- Construct Output Vector Doc – Step 7: This step invokes the customers implementation of our Sagemaker interface to construct an output Vector Doc from combining the generated vector embeddings and the original Feature Doc. Let’s call this Vector Doc. Here is the implementation that we are using: CommonCrawlSagemakerReader.java
- Write Vector Doc to Momento – Step 8-9: The Vector doc is then written to Momento Vector Index by our write connector – it currently uses 3 threads, each of which can attempt to do a add_items with a batch size of 150 documents.
- Write Error Docs to S3 – Step 10: Any errors that were encountered during the pipeline, either in momento write or earlier, are written to S3 as an error document. Here is an example error doc:
Search
A quick python script to check whether our embeddings were being indexed and are returning search results:
ScriptResultsErrors
Following is how Momento errors are classified when writing to Momento Vector Index.
On This Page
Overview
Highlights
Supported Destinations
Common Configurations
Usecases
↳Momento Vector Index
↳Config
↳Access Grants
↳Implementation
↳Errors
↳Kinesis
↳Config
↳Access Grants
↳DynamoDB
↳Config
↳Access Grants
↳S3
↳Config
↳Access Grants
↳S3 Aggregate File
↳Config
↳Access Grants
↳SQS FIFO
↳Config
↳Access Grants
↳SQS Standard
↳Config
↳Access Grants
↳Kafka Serverless
↳Config
↳Access Grants
↳Kafka Provisioned
↳Config
↳Access Grants
The Resonance Labs, LLC
P.O. Box 3223
Redmond, WA 98073, USA